J’ai enfin du stockage performant après plusieurs années
Table of Contents
Cela fait maintenant très longtemps que j’ai des problèmes de performance sur le stockage dans mon Homelab. J’ai enfin trouvé la cause de ces problèmes, après plusieurs années.
Je vais faire un historique des stockages que j’ai eu dans mon lab au fil du temps, et je résumerai ce que j’aurais aimé qu’on me dise à ce sujet.
Historique de mon stockage
Stockage local
J’ai commencé, comme beaucoup, avec quelques HDD (disques durs) sur mes différents serveurs qui exécutaient mon cluster VMware ESXi (maintenant vSphere Hypervisor). Il s’agissait de disques SAS de 10k ou 15k tours/minutes.
Ces disques étaient attachés aux contrôleurs SAS (Dell PERC) de mes différents serveurs, en RAID1 ou RAID5. Ça fonctionnait assez bien, mais la performance était faible.
J’ai donc changé après quelques années pour des SSD grand public SATA, en général des Crucial MX ou des Samsung EVO de génération la plus récente au moment de l’achat.
Ça fonctionnait bien, c’était simple.
Alors, pourquoi changer ?
Les clusters VMware vSphere utilisaient DRS (VMware Distributed Resource Scheduler), qui peut migrer des VMs automatiquement en fonction de la charge de l’hyperviseur, ou bien évacuer un hyperviseur pour le mettre en maintenance (par exemple, pour procéder à des mises à jour).
Malheureusement, DRS requiert du stockage partagé, donc du stockage accessible depuis plusieurs hôtes simultanément pour procéder à ces migrations automatiques. Le stockage local désactive automatiquement toute migration automatique, ce qui est devenu un problème avec l’augmentation du nombre de VMs sur mon cluster.
Un SAN/NAS home-made
Je suis un très grand afficionado de ZFS. C’est un système de fichiers avec gestion des volumes, qui sait détecter et corriger les erreurs silencieuses, contrairement aux contrôleurs matériels (une très bonne vidéo de Level1Techs traite ce sujet).
ZFS scale bien (d’où son nom, Zettabyte File System), et est, quand il est bien géré, extrêmement robuste. J’ai donc voulu m’en servir comme stockage partagé. Un achat de 4x Samsung 970 EVO plus tard, j’ai monté une paire de VDEVs en mirroir, une construction recommandée pour la performance sur ZFS (équivalement d’un RAID10), au prix d’un efficacité de stockage de 50% (chaque donnée est répliquée deux fois en mirroir, et non pas par parité).
Dans un premier temps, j’ai exposé ce stockage en iSCSI avec un zVOl (un volume virtuel ZFS) à mon cluster VMware. iSCSI étant un protocole qui expose du stockage en bloc (et non pas un système de fichier), VMware va créer un système de fichiers VMFS, son filesystem propriétaire (qui gère notamment les accès concurrentiels par plusieurs hôtes) par-dessus.
J’attendais pas mal de ce stockage car j’avais dédié un serveur (un petit Dell R320) à cet effet avec CentOS 7 en bare-metal, une interface réseau Intel X520 et 4 SSD performants.
Et malheureusement, la performance était extrêmement mauvaise. À l’époque, l’élément le plus demandeur de mon lab était Zabbix, qui monitorait tout chez moi (mon réseau domestique, mon lab, ses hôtes, son stockage, etc…). Et Zabbix n’arrivait même plus à remonter les erreurs et crashait régulièrement tellement il y avait d’IOwait (le CPU attend des “nouvelles” du stockage, qui tardent trop et bloquent tout).
Je n’ai malheureusement plus de métriques car cela fait trop longtemps, mais je me souvient de FIO, un outil de benchmark stockage, qui faisait état d’environ 3000 IOPS sur des écritures aléatoires en bloc de 4K. Pour comparaison, un seul 970 EVO local tourne aux alentours de 240 000 IOPS sur ce même test.
J’ai tenté beaucoup de choses à l’époque, ait basculé sur NFS à la place de iSCSI, sans succès. J’avais aussi acheté un SSD Intel Optane (technologie très différente d’un SSD classique, beaucoup plus rapide), mais c’était la version bureau conçue pour accélérer les disques durs (Intel Optane M10), pas la “vraie” technologie Optane derrière l’Intel Optane 900P, par exemple, qui ne donne pas du tout les mêmes performances.
J’ai fini par jeter l’éponge et revenir sur du stockage local, parce que la performance était beaucoup trop faible, et surtout parce que je n’aimais pas que mon cluster entier dépende d’un seul hôte, et je n’avais ni la place ni l’envie de monter de la haute disponibilité sur le stockage.
VMware vSAN
VMware vSAN est une solution de stockage propriétaire de VMware, qui permet de monter un SAN virtuel par-dessus du stockage local sur plusieurs hôtes VMware vSphere.

Ayant utilisé mes Samsung 970 EVO de l’époque, j’avais acheté trois Samsung 980 PRO (qui ne sont pas des SSD de gamme pro, contrairement à ce que leur nom laisse penser), un par hôte, pour cache, et réutilisé mes Samsung EVO et Crucial MX pour le stockage, ce qui correspond à une architecture vSAN “all-flash”.
Tous ces SSD étant des modèles grand public, ils ne figurent par sur la liste de compatibilité VMware (aussi appelée HCL, Hardware Compatibility List).
Et ça donne quoi ?
C’était, encore une fois, très faible. La performance était meilleure que mon SAN improvisé, mais la performence globale était encore bien en dessous d’un SSD SATA seul, ce qui devenait un sérieux goulot d’étranglement pour mes nombreuses VMs. Je n’ai malheureusement plus non plus de métriques à partager, ayant migré.
Je suis resté relativement sur cette solution, faute de mieux. La performance était tout juste suffisante tant que VMware n’avait pas besoin de faire de la reconstruction du stockage (par exemple, après un reboot inopiné d’un hyperviseur).
J’ai monté un cluster Kubernetes au-dessus de cette solution, sur lequel j’ai déployé la majorité de mes workloads, et ça a commencé à ne plus suffire.
Premièrement, je n’ai jamais réussi à exposer le stockage vSAN à mon cluster Kubernetes. vSAN en est capable, il est notamment utilisé avec VMware Tanzu, la distribution Kubernetes de VMware. Mais j’utilise pour ma part du K3s ou bien du RKE2 en distribution Kubernetes.
J’ai tenté d’installer le CPI VMware (le CPI, ou Cloud Provider Interface, est le composant Kubernetes qui gère l’intégration du cluster avec l’infrastructure sous-jacente), sans succès. C’est un pré-requis pour le CSI vSAN (le CSI, ou [Container Storage Interface], est le composant Kubernetes qui gère le stockage de Kubernetes).
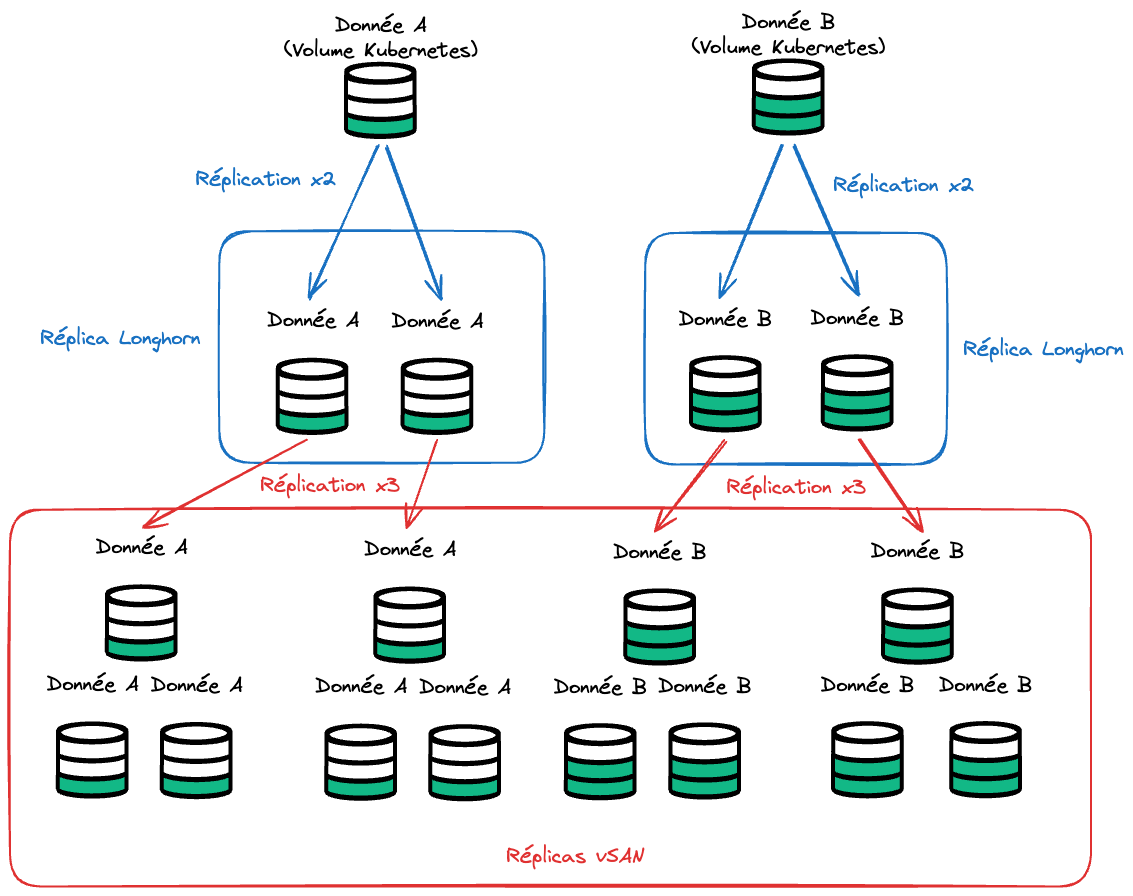
Faute d’avoir réussi à utiliser le CSI vSAN, je me suis donc rabattu sur Longhorn, un CSI de Rancher qui gère du stockage virtuel au-dessus du stockage rattaché aux noeuds Kubernetes. Longhorn est simple d’utilisation et puissant, et j’en ai été dans l’ensemble très satisfait.
En revanche, son utilisation a commencé à poser problème. Longhorn est normalement fait pour utiliser du stockage physique, et il gère ainsi lui-même la redondance et parité des données. Dans mon cas, les volumes étaient des volumes virtuels vSAN, qui avaient donc aussi leur propre redondance et parité.
L’inconvénient, lorsque l’on “empile” des couches de stockage avec leur propre redondance et parité, c’est que les pénalités s’accumulent exponentiellement. vSAN veut répliquer sa donnée plusieurs fois, mais Longhorn aussi. Par exemple, si vSAN réplique sa donnée trois fois, et Longhorn deux fois, et bien la donnée va être répliquée six fois (2 réplicas Longhorn x 3 réplicas vSAN).
Et avec cette “super-réplication” vient la pénalité sur l’efficacité du stockage et la pénalité sur la performance. En d’autres termes, chaque donnée est répliquée six fois, donc prend six fois plus de place, et chaque écriture est faite six fois, ce qui est beaucoup plus lent.
vSAN étant déjà très juste au niveau de sa performance, Longhorn a grandement accentué les problèmes, une nouvelle fois.
Proxmox + Ceph
Enfin, début 2024, j’ai migré de VMware vSphere vers Proxmox Virtuel Environment (j’ai prévu quelques posts pour en parler plus en détails). Proxmox ne propose évidemment pas vSAN, technologie propriétaire, mais une alternative similaire : Ceph.
Ceph n’est pas spécialement lié à Proxmox, il est simplement intégré dedans, il s’agit d’un logiciel ouvert, entièrement séparé. J’ai donc dû migrer mes VMs de vSAN à Ceph, espérant au passage avoir enfin une performance décente.
Ceph n’a pas de cache comme vSAN, je n’ai donc plus utilisé mes SSD NVMe et me suis rabattu sur mes Samsung EVO en SATA uniquement.

J’ai commencé par migrer mon noeud Zabbix, et me suis aperçu que sa performance était assez bonne. Je ne l’ai pas benchmarké, mais il semblait assez rapide, j’avais à nouveau espoir que mes ennuis de stockage soient terminés.
Et puis, j’ai commencé à migrer mes noeuds Kubernetes. Et ça a été le drame. La performance s’est avérée bien pire que vSAN, sans doute à cause de l’absence de cache (ou plutôt, cache-misère).
Je vous laisse voir par vous-même :

On a quasi tout le temps des pics de latence d’écriture à quelques centaines de milliseconde. Pas de quoi faire rougir un disque dur 5400 RPM des années 2000.
En revanche, j’ai pu profiter du CSI Rook sur mes clusters Kubernetes, et ainsi supprimer Longhorn. Rook est un CSI Kubernetes qui gère du Ceph, mais qui peut aussi s’interfacer avec un cluster Ceph externe, ici, celui intégré à mon cluster Proxmox. Et avec à la clé une très augmentation de l’efficacité du stockage.
Cause des mauvaises performances
Après quelques années à regarder la performance de mon stockage passer de plutôt mauvaise à franchement catastrophique sans vraiment m’en soucier, j’ai fini par me pencher un peu plus sérieusement sur le sujet.
Après tout, j’ai des serveurs relativement modernes, du stockage performant sur le papier, et un réseau 10Gbps partout, avec minimum 2x10Gbps par serveur.
Je n’ai pas une très grande expérience du stockage, en particulier dans le monde professionnel, donc j’ai fait quelques recherches, déjà à l’époque de mon cluster vSAN.
Le problème, avec vSAN (et les produits VMware en général), c’est que le monde industriel préfère donner des recommendations sans les causes de ces recommendations. Parmi ces recommandations, on trouve régulièrement celles-ci, aussi bien de VMware que de personnes qui répètent la même chose sur Reddit:
- Réseau de stockage 10Gbps obligatoire pour du flash
- SSD “enterprise-grade” obligatoires
Le premier coche est rempli, j’ai des NIC Intel X520 ou X710 (2/4 ports 10Gbps), recommandées par VMware. Le second, non. J’ai très longtemps attribué ce conseil d’avoir des SSD de classe entreprise à deux facteurs :
- Ces conseils sont formulés pour des cluster opérés par des entreprises, où la fiabilité est de mise. Mon lab reste un lab, je ne m’attends pas à avoir les mêmes workloads que les grande entreprises. Avec un SSD entreprise, on bénéficie normalement d’un support constructeur, d’une conformité aux recommandations VMware en cas de besoin de support, etc…
- Leur endurance est grandement supérieure aux SSD grand-public. On parle d’une échelle entièrement différente, mais encore une fois, je ne m’attends pas à ecrire plusieurs centaines de Giga-octets sur chaque SSD par jour, même avec les pénalités des stockages distribués.
La cause de cette seconde recommandation n’est par ailleurs jamais expliquée. Le conseil est toujours le même : “Tenez-vous en à la liste de compatibilité VMware”, sans dire pourquoi. J’ai donc choisi de l’ignorer, puisqu’on ne m’en donnait pas la cause.
J’avais tort.
Après ma migration sur Ceph, j’ai recommencé à m’intéresser au sujet, un peu plus sérieusement cette fois. Et j’ai trouvé une piste après quelques recherches.
Il y a une autre différence fondamentale entre un SSD grand-public et un SSD entreprise/DC : le PLP.
Le PLP (ou Power-Loss Protection) est un moyen pour le SSD d’avoir toujours du courant, même lorsqu’il n’est plus alimenté. En général, cela se résume simplement à quelques condensateurs, qui permettent donc au SSD de s’auto-alimenter quelques instants.
Le but du PLP est de permettre au SSD de pouvoir écrire la donnée qu’il a en attente, même si l’éléctricité est coupée brutalement. C’est important pour la fiabilité de la donnée, et c’est pour cette raison que sa présence est quasi-systématique sur les SSD entreprise.
Mais pourquoi le PLP aurait un impact sur la performance ?
C’est là où la communauté Ceph est un peu plus explicative sur le sujet. Je ne peux pas le confirmer avec vSAN, technologie propriétaire, mais je suis quasi-certain que le problème est le même.
En fait, PLP permet au SSD de changer de comportement lorsque le logiciel demande une fsync. fsync est une instruction en C qui demande d’écrire toute la donnée en attente sur le stockage. Lorsqu’un SSD reçoit un fsync, il est donc tenu de vérifier que la donnée est écrite et pérenne. Il ne peut répondre “OK” que quand il est sûr que la donnée est bien écrite.
Et c’est là que PLP intervient. Sur un SSD grand-public, quand on demande un fsync, son seul moyen d’être sûr que la donnée est bien écrite est de l’écrire sur la NAND et de ne répondre que quand la donnée est bien écrite. Le problème, c’est que la NAND d’un SSD grand-public récent n’est pas très rapide (d’où la présence quasi-systématique d’un cache DRAM).
Le temps passé à écrire sur la NAND est du temps passé à bloquer les écritures latentes.
Un SSD enterprise n’a pas cette contrainte. Il est sûr de pouvoir écrire la donnée quoiqu’il arrive puisqu’il peut s’auto-alimenter assez longtemps pour l’écrire en autonomie. Quand on lui demande un fsync, il répond donc immédiatement “OK” et continue à accepter les écritures.
Ceph ou vSAN ont parmis leurs objectifs la consistence. Ils ne peuvent pas se permettre de corrompre de la donnée. Dans le cas de Ceph (et sans doute de vSAN), cela se traduit donc par l’envoi très régulier de l’instruction fsync, et par conséquent de l’arrêt de l’acceptation des écritures sous-jacente des SSD grand-public. Et pour cause donc logiquement une très grosse augmentation de la latence des écritures.
La solution
En 2024, certains SSD entreprise SATA sont devenus très abordables, d’occasion ou non. Je ne recommande en général pas d’acheter du stockage d’occasion, car c’est un support qui s’use. Je fais une exception pour les SSD entreprise de par leur endurance exceptionnelle. Un SSD entreprise d’occasion a dans 99% une autonomie bien supérieure à un SSD grand-public neuf.
J’ai donc jeté mon dévolu sur des Samsung PM883. C’est un SSD relativement moderne (2018), accessible (aux alentours d’une centaine d’euros pour la version 960 Go d’occasion, voire neuf, pas si éloigné du prix d’un SSD grand-public neuf) et performant (peut saturer l’interface SATA3 en lecture/écriture séquentielle).
Et voici le résultat sur mon cluster Ceph :
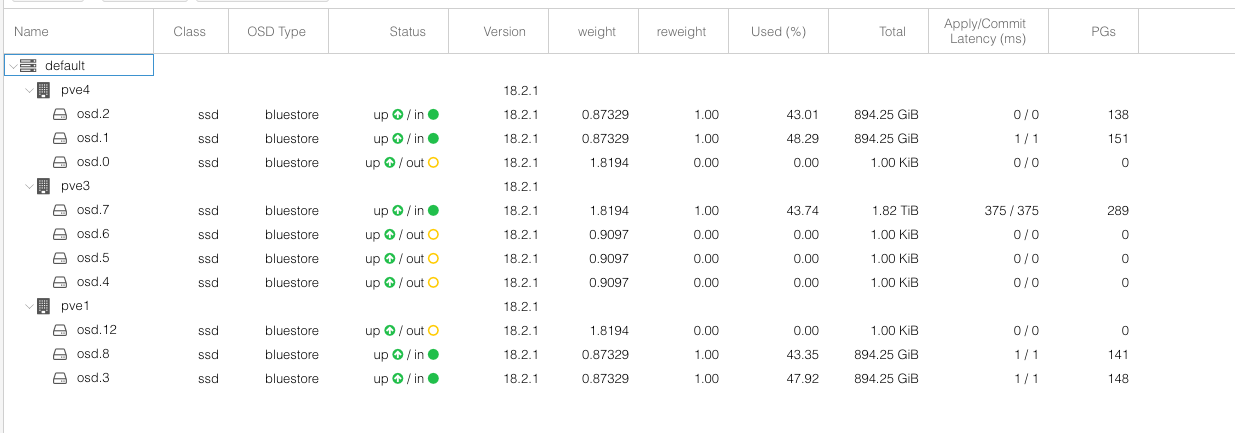
Les OSD représentent chacun un disque sur Ceph, ceux qui sont actifs sont ceux en “in” (les “out” sont en cours de décomissionnement), et la “Apply/Commit latency” indique la latence d’écriture sur les SSD en ms.
Il y a cette sur cette image quatre OSD portés par les Samsung PM883, et un seul OSD porté par un Samsung EVO 870. Je vous laisse deviner lequel est lequel.
Un test avec fio sur une VM montre la très nette différence :
Avant :
fio --name fio_test_file --direct=1 --rw=randwrite --bs=4k --size=20M --numjobs=16 --time_based --runtime=180 --group_reporting --norandommap
fio_test_file: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=1
...
fio-3.25
Starting 16 processes
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
Jobs: 16 (f=16): [w(16)][100.0%][eta 00m:00s]
fio_test_file: (groupid=0, jobs=16): err= 0: pid=2899883: Sun Feb 25 12:32:43 2024
write: IOPS=737, BW=2951KiB/s (3022kB/s)(519MiB/180159msec); 0 zone resets
clat (msec): min=9, max=2438, avg=21.63, stdev=46.91
lat (msec): min=9, max=2438, avg=21.65, stdev=46.91
clat percentiles (msec):
| 1.00th=[ 13], 5.00th=[ 13], 10.00th=[ 14], 20.00th=[ 14],
| 30.00th=[ 16], 40.00th=[ 16], 50.00th=[ 17], 60.00th=[ 18],
| 70.00th=[ 20], 80.00th=[ 22], 90.00th=[ 27], 95.00th=[ 40],
| 99.00th=[ 79], 99.50th=[ 116], 99.90th=[ 567], 99.95th=[ 1183],
| 99.99th=[ 2089]
bw ( KiB/s): min= 112, max= 4580, per=100.00%, avg=3070.65, stdev=72.39, samples=5524
iops : min= 16, max= 1142, avg=760.82, stdev=18.09, samples=5524
lat (msec) : 10=0.01%, 20=74.47%, 50=22.61%, 100=2.31%, 250=0.33%
lat (msec) : 500=0.14%, 750=0.06%, 1000=0.01%, 2000=0.06%, >=2000=0.01%
cpu : usr=0.06%, sys=0.67%, ctx=133815, majf=0, minf=204
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : =0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,132926,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=2951KiB/s (3022kB/s), 2951KiB/s-2951KiB/s (3022kB/s-3022kB/s), io=519MiB (544MB), run=180159-180159msec
Disk stats (read/write):
sda: ios=0/133627, merge=0/48, ticks=0/2892469, in_queue=2904210, util=99.18%
Après :
fio --name fio_test_file --direct=1 --rw=randwrite --bs=4k --size=20M --numjobs=16 --time_based --runtime=180 --group_reporting --norandommap
fio_test_file: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=1
...
fio-3.25
Starting 16 processes
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: Laying out IO file (1 file / 20MiB)
fio_test_file: (groupid=0, jobs=16): err= 0: pid=3794650: Mon Feb 26 15:25:45 2024
write: IOPS=6110, BW=23.9MiB/s (25.0MB/s)(1093MiB/45785msec); 0 zone resets
clat (usec): min=1378, max=62763, avg=2579.51, stdev=689.00
lat (usec): min=1387, max=62769, avg=2588.63, stdev=689.13
clat percentiles (usec):
| 1.00th=[ 1811], 5.00th=[ 1975], 10.00th=[ 2073], 20.00th=[ 2212],
| 30.00th=[ 2311], 40.00th=[ 2409], 50.00th=[ 2507], 60.00th=[ 2573],
| 70.00th=[ 2704], 80.00th=[ 2802], 90.00th=[ 3032], 95.00th=[ 3359],
| 99.00th=[ 4686], 99.50th=[ 5342], 99.90th=[ 8291], 99.95th=[11207],
| 99.99th=[23462]
bw ( KiB/s): min=19938, max=26176, per=100.00%, avg=24456.64, stdev=63.83, samples=1456
iops : min= 4980, max= 6544, avg=6113.54, stdev=16.01, samples=1456
lat (msec) : 2=5.91%, 4=91.84%, 10=2.19%, 20=0.05%, 50=0.01%
lat (msec) : 100=0.01%
cpu : usr=0.40%, sys=4.19%, ctx=280168, majf=0, minf=204
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,279788,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=23.9MiB/s (25.0MB/s), 23.9MiB/s-23.9MiB/s (25.0MB/s-25.0MB/s), io=1093MiB (1146MB), run=45785-45785msec
Disk stats (read/write):
sda: ios=0/278997, merge=0/12, ticks=0/701150, in_queue=701283, util=100.00%
Et la latence qui a chuté dès que l’OSD avec le dernier SSD Samsung EVO a fini d’être évacué :

Le stockage est maintenant réactif, et largement assez performant pour mon usage, même pendant une reconstruction de Ceph.