Création d’une plateforme de SSO hautement disponible - Partie 2
Table of Contents
Ayant choisi notre solution d’authentification, à savoir Authentik, il s’agit maintenant de la déployer. Comme mentionné précédemment, ce déploiement doit répondre à des contraintes de haute disponibilité, il faut donc que le déploiment prenne en compte ces contraintes.
Pré-requis
J’ai relativement peu de contraintes, mais il convient de les lister avant de réfléchir au déploiement.
- Haute disponibilité, on veut que la plateforme reste joignable en cas de crash d’une de ses VMs (machines virtuelles).
- Pas de contraintes de performance. Ce projet répond à un besoin personnel d’authentification, on ne s’attend pas à avoir un gros volume de requêtes. La plupart de mes applications ne sont même pas exposées sur internet, ce qui limite la probabilité d’une attaque par déni de service (DoS/DDoS) sur l’authentification.
- Le cluster doit avoir une taille “raisonnable” (aussi petit que possible, mais sans compromettre nos objectifs de disponibilité). Nous allons le voir, il y a pas mal de composants logiciels différents à déployer, qui impliquent beaucoup de VMs différentes.
Le premier point n’est pas anodin, la disponibilité d’un service dépend de son maillon le plus faible. Autrement dit, si l’on veut que la plateforme reste accessible en cas de crash de n’importe lequel de ses éléments, cela signifique que chaque élément doit être redondé.
Composants logiciels
Nous allons maintenant lister la liste des composants logiciels à déployer. En effet, Authentik a un certain nombre de dépendances :
- Authentik, le logiciel principal.
- PostgreSQL, la base de données.
- Redis, serveur de cache haute performances.
- Microsoft Active Directory, pour fournir les identités au travers de LDAP.
- Keepalived, pour créer des VIP qui pointent vers un noeud fonctionnel.
Chacun de ces logiciels prend en charge la disponibilité plus ou moins simplement.
Déploiement
L’ordre de déploiement n’a pas une grande importance, si ce n’est que l’on veut déployer Authentik à la toute fin, car c’est lui qui dépend des différents logiciels.
Matériel
Je vais déployer l’ensemble de la solution où je travaille, Outscale.
La solution IaaS d’Outscale a une API “maison” et une API compatible AWS EC2, on peut ainsi utiliser aws-cli pour créer des ressources, mais aussi oapi-cli, ou encore Terraform.
Je vais utiliser Terraform pour déployer une architecture sur un VPC, avec deux subnets. Il y aura un subnet “interne” qui contiendra l’ensemble des applicatifs, à l’exception des load balancers, qui seront déployés dans le second subnet, nommé “public”.
PostgreSQL

PostgreSQL est un des SGBD (système de gestion des bases de données) les plus populaires.
Il est très répandu en entreprise et utilisé par de très nombreux logiciels à travers le monde.
En revanche, il ne gère nativement pas la haute disponibilité, celle-ci doit être gérée par des solutions tierces. En raison de sa popularité, il en existe de très nombreuses.
Dans mon cas, j’ai choisi Patroni. Il est relativement simple à configurer, est assez éprouvé (en particulier sur Kubernetes), maintenu, et puissant.
Patroni a lui-même des pré-requis, notamment pour stocker sa configuration et “découvrir” ses pairs au sein du cluster. Il supporte de nombreuses solutions, comme Consul ou etcd. Je vais utiliser etcd3.
La plupart des clusters PostgreSQL hautement disponibles exigent un nombre impair de noeuds, pour maintenir un quorum (un vote à la majorité des noeuds fonctionnels). Un seul noeud ne convient pas non plus, puisqu’en cas de panne, le cluster entier tomberait. Cela porte donc notre nombre minimum de noeuds à trois.
etcd3
Sa configuration est plutôt simple, on donne un nom au noeud, un couple certificat/clé privée et une CA pour qu’il valide ses pairs et chiffre ses communications.
Il existe plusieurs façons pour etcd de lui donner le nom de ses pairs, l’une de celles-ci est l’auto-discovery. Un serveur central fournit une API sur laquelle etcd s’enregistre, et découvre les autres noeuds déjà enregistrés. On peut déployer un serveur discovery interne, mais pour la simplicité j’ai choisi d’utiliser celui qui est public.
Pour ce faire, un simple :
curl https://discovery.etcd.io/new\?size\=3
suffit. On nous donne en réponse une URL simple qui est à configurer dans la variable d’environnement ETCD_DISCOVERY, définie dans /etc/defaults/etcd.
Patroni
On installe ensuite Patroni. Sa configuration doit être créée, au chemin /etc/patroni/config.yml.
Parmi les éléments à configurer, il y aura la connexion au cluster etcd3 :
etcd3:
host: 'pgsql-1.domaine-interne-sso.com:2379'
cacert: /etc/ssl/certs/ca-certificates.crt
cert: /etc/ssl/letsencrypt/pgsql-1.domaine-interne-sso.com.cert.pem
key: /etc/ssl/letsencrypt/pgsql-1.domaine-interne-sso.com.key.pem
protocol: https
Patroni va également s’occuper de configurer PostgreSQL pour nous, il faut donc lui fournir la configuration des utilisateurs d’origine (il ne gère pas le changement, donc les utilisateurs sont appliqués une seule fois, à la création du cluster). Il faudra également lui donner la configuration de pg_hba, la partie qui configure qui a le droit de s’authentifier et où :
bootstrap:
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator ::1/128 md5
- host all all 0.0.0.0/0 md5
- host all all ::/0 md5
- host replication replicator <ip pgsql-1>/32 md5
- host replication replicator <ip pgsql-2>/32 md5
- host replication replicator <ip pgsql-3>/32 md5
postgresql:
listen: '*:5432'
connect_address: 'pgsql-1.domaine-interne-sso.com:5432'
data_dir: /var/lib/patroni/data
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: '<redacted>'
superuser:
username: postgres
password: '<redacted>'
parameters:
unix_socket_directories: '/var/run/postgresql'
bin_dir: /usr/lib/postgresql/16/bin/
Pour référence, la configuration complète de mon fichier ressemble à ça :
scope: postgres
namespace: /db/
name: pgsql-1
restapi:
listen: '*:8008'
connect_address: 'pgsql-1.domaine-interne-sso.com:8008'
etcd3:
host: 'pgsql-1.domaine-interne-sso.com:2379'
cacert: /etc/ssl/certs/ca-certificates.crt
cert: /etc/ssl/letsencrypt/pgsql-1.domaine-interne-sso.com.cert.pem
key: /etc/ssl/letsencrypt/pgsql-1.domaine-interne-sso.com.key.pem
protocol: https
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator ::1/128 md5
- host all all 0.0.0.0/0 md5
- host all all ::/0 md5
- host replication replicator <ip pgsql-1>/32 md5
- host replication replicator <ip pgsql-2>/32 md5
- host replication replicator <ip pgsql-3>/32 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: '*:5432'
connect_address: 'pgsql-1.domaine-interne-sso.com:5432'
data_dir: /var/lib/patroni/data
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: '<redacted>'
superuser:
username: postgres
password: '<redacted>'
parameters:
unix_socket_directories: '/var/run/postgresql'
bin_dir: /usr/lib/postgresql/16/bin/
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
On a donc aussi activé l’API REST de Patroni, qui nous servira notamment à trouver le noeud principal avec Keepalived, et y monter la VIP.
Keepalived
Notre cluster PostgreSQL à trois noeuds est désormais fonctionnel, mais il nous manque un moyen pour communiquer avec.
En effet, seul le noeud “master” peut accepter des écritures, les autres noeuds peuvent uniquement fournir les données en lecture.
Un schéma classique d’architecture consiste à ajouter une paire de load-balancer devant le cluster, par exemple avec PGBouncer.
Dans mon cas, comme expliqué dans le préambule, la performance ne m’intéresse pas, et je veux garder mon cluster aussi petit que possible. J’ai donc choisi de m’affranchir entièrement du load balancer, et d’uniquement monter une VIP sur le noeud master. En d’autres mots, nous ne distribuerons pas les lectures sur les différents noeuds du cluster, un seul noeud s’occupera de gérer les lectures/écritures, pendant que les autres se contenteront de répliquer la donnée en cas de panne.
Nous allons donc nous servir de Keepalived, un logiciel libre implémentant le protocole VRRP, bien connu des administrateurs réseau.
Pour faire bref, ce protocole fait parler ses différents noeuds entre eux pour choisir un noeud qui portera une VIP (IP virtuelle), associée à une adresse Mac virtuelle. Lorsque le noeud porteur de la VIP tombe, VRRP bascule (très rapidement), cette VIP+Mac à une autre noeud sain.
Keepalived est assez puissant, et on peut implémenter des vérifications plus complexes au travers de script. Dans notre cas, nous allons utiliser un simple cURL sur l’API REST de Patroni, pour voir qui est le noeud master, et y associer la VIP.
vrrp_script SC_100 {
script "/usr/bin/curl -X GET -I --fail http://localhost:8008/primary"
user root
}
vrrp_instance VI_100 {
state MASTER
interface eth0
virtual_router_id 100
priority 100
advert_int 1
authentication {
auth_type AH
auth_pass <redacted>
}
virtual_ipaddress {
<vip>/32
}
virtual_ipaddress_excluded {
}
track_script {
SC_100
}
}
Microsoft Active Directory

Je vais assez peu m’étendre le sujet car la configuration est très dépendante de l’environnement et la solution est assez complexe à prendre en main. De manière générale, j’ai un domaine Active Directory pour gérer l’authentification centralisée des PC et Mac de chez moi. Active Directory implémente LDAP avec des extensions propriétaires, mais on peut parfaitement utiliser LDAP pour lui parler.
J’ai donc monté une paire de RODC (contrôleurs de domaine en lecture seule), qui répliquent l’ensemble des données du domaine depuis chez moi, à travers un VPN. Les RODC continuent de fonctionner en cas de panne des contrôleurs de domaine sources pour les identités présentent dans le cache. Par exemple, si le VPN coupe, le RODC ne peut pas parler aux PDC (contrôleurs de domaines principaux/primaires), mais continuera d’authentifier les utilisateurs présents dans son cache.
Ces politiques sont paramétrables, en fonction des exigences de sécurité. On peut par exemple choisir de ne pas répliquer le mot de passe de certains utilisateurs critiques, mais alors le RODC doit pouvoir parler aux PDC pour les authentifier.
Redis

Redis est un serveur de cache performant. Il stocke en RAM les données que ses clients lui transmettent (et éventuellement les réplique sur du stockage froid).
La donnée sur Redis est rarement critique de par sa nature, cela signifie que la majorité des logiciels tolèrent le fait que Redis perde ses données sans cesser de fonctionner. En revanche, la plupart des logiciels, dont Authentik, requièrent qu’un serveur leur réponde pour fonctionner.
L’hypothèse où Redis perd ses données est documentée chez Authentik. On nous y explique qu’en cas de perte des données, les utilisateurs seront déauthentifiés. C’est acceptable dans mon cas, mais comme il nous faut un serveur fonctionnel dans tous les cas, nous allons déployer un cluster Redis Sentinel.
Redis Sentinel est un second logiciel qui interroge différents serveurs Redis et évalue qui est fonctionnel et qui ne l’est pas. Comme PostgreSQL, Sentinel a besoin d’un quorum pour fonctionner, afin d’éviter un scénario de split-brain (le cas où une coupure, par exemple réseau entre plusieurs noeuds, fait croire à plusieurs noeuds simultanément que leur(s) partenaire(s) est/sont tombé(s) et donc qu’ils sont maîtres).
Redis Sentinel a en revanche un inconvénient majeur, c’est que l’applicatif doit le prendre en charge. Il faut donc que le logiciel parle à Sentinel pour obtenir le noeud maître, et lui parler. La plupart des logiciels le prennent en charge, mais ce n’est malheureusement pas le cas d’Authentik. Une issue GitHub à ce sujet existe.
Keepalived
Pour contourner ce problème, nous allons à nouveau recourir à Keepalived. Il va cette fois-ci parler à Redis Sentinel, avec qui la communication est heureusement simple (il suffit d’envoyer les messages directement en TCP). On peut aussi se servir de redis-cli, un wrapper, pour discuter avec lui.
Nous allons à nouveau nous servir d’un script donc pour communiquer avec Sentinel. Le noeud maître selon Sentinel sera le porteur de la VIP, à laquelle Authentik parlera.
La configuration de Keepalived ressemble à ça :
vrrp_script SC_101 {
script "/opt/redis_master.sh"
user root
}
vrrp_instance VI_101 {
state MASTER
interface eth0
virtual_router_id 101
priority 100
advert_int 1
authentication {
auth_type AH
auth_pass <redacted>
}
virtual_ipaddress {
<vip>/32
}
virtual_ipaddress_excluded {
}
track_script {
SC_101
}
}
Le script bash référencé, stocké dans /opt/redis_master.sh, contient ce qui suit :
#!/bin/bash
# This is a helper script to check if the current redis instance is the master of the replication scheme.
# This accounts for cases when the local redis instance is down. Since that means this node can't be the master, we handle
# that gracefully.
REPLICATION_DATA=`redis-cli -a "<mot de passe>" info replication 2> /dev/null`
if [ $? -ne 0 ]; then
exit 1;
fi
# Check the data for master information
echo $REPLICATION_DATA | grep -q 'role:master'
exit $?
J’ai adapté ce script depuis un article d’un blog en anglais répondant à un problème similaire au mien.
Authentik
Les pré-requis d’Authentik étant déployés, nous pouvons dès maintenant installer Authentik. Authentik propose deux modes de déploiement, un premier basé sur Kubernetes, que nous n’allons pas utiliser en raison de l’indépendance qu’il doit avoir (se référer à la partie 1 pour les raisons plus détaillées).
Le second mode de déploiement repose donc sur Docker. Je vais donc déployer deux noeuds, sur lesquels je vais déployer le container Authentik web, et un worker. J’utiliserai donc Ansible pour ce faire, car c’est lui qui gère la plupart de mes déploiements hors Kubernetes.
La task Ansible est la suivante :
- name: setup authentik
community.docker.docker_container:
name: authentik
image: "ghcr.io/goauthentik/server:{{ authentik.version }}"
command: server
ports:
- "9443:9443"
env:
AUTHENTIK_SECRET_KEY: "{{ authentik.secret_key }}"
AUTHENTIK_REDIS__HOST: "{{ authentik.redis.host }}"
AUTHENTIK_REDIS__PASSWORD: "{{ authentik.redis.password }}"
AUTHENTIK_POSTGRESQL__HOST: "{{ authentik.postgres.host }}"
AUTHENTIK_POSTGRESQL__USER: "{{ authentik.postgres.username }}"
AUTHENTIK_POSTGRESQL__PASSWORD: "{{ authentik.postgres.password }}"
AUTHENTIK_STORAGE_MEDIA_BACKEND: s3
AUTHENTIK_STORAGE_MEDIA_S3_ENDPOINT: "{{ authentik.s3.endpoint }}"
AUTHENTIK_STORAGE_MEDIA_S3_BUCKET__NAME: "{{ authentik.s3.bucket }}"
AUTHENTIK_STORAGE_MEDIA_S3_ACCESS__KEY: "{{ authentik.s3.access_key }}"
AUTHENTIK_STORAGE_MEDIA_S3_SECRET__KEY: "{{ authentik.s3.secret_key }}"
restart_policy: always
throttle: 1
La partie S3 pointera directement vers le service Outscale Object Storage, OOS pour les intimes, qui propose un stockage object avec une API AWS S3-compatible.
Bilan
Nous l’avons vu, même pour un service relativement simple, gérer de la haute disponibilité sur l’ensemble des composants nécessite pas mal de logiciels différents, qui tournent par principe sur des VMs différentes.
L’idée étant que les briques soient indépendantes les unes des autres. Un serveur ou une VM qui lâche parce qu’il aura crashé (en cas de panne matérielle, par exemple, mais pas seulement, cela peut aussi passer par un usage CPU trop important, ou un disque rempli, entre autres) n’impactera qu’une instance d’un composant à la fois.
L’architecture finale est représentée dans ce schéma :
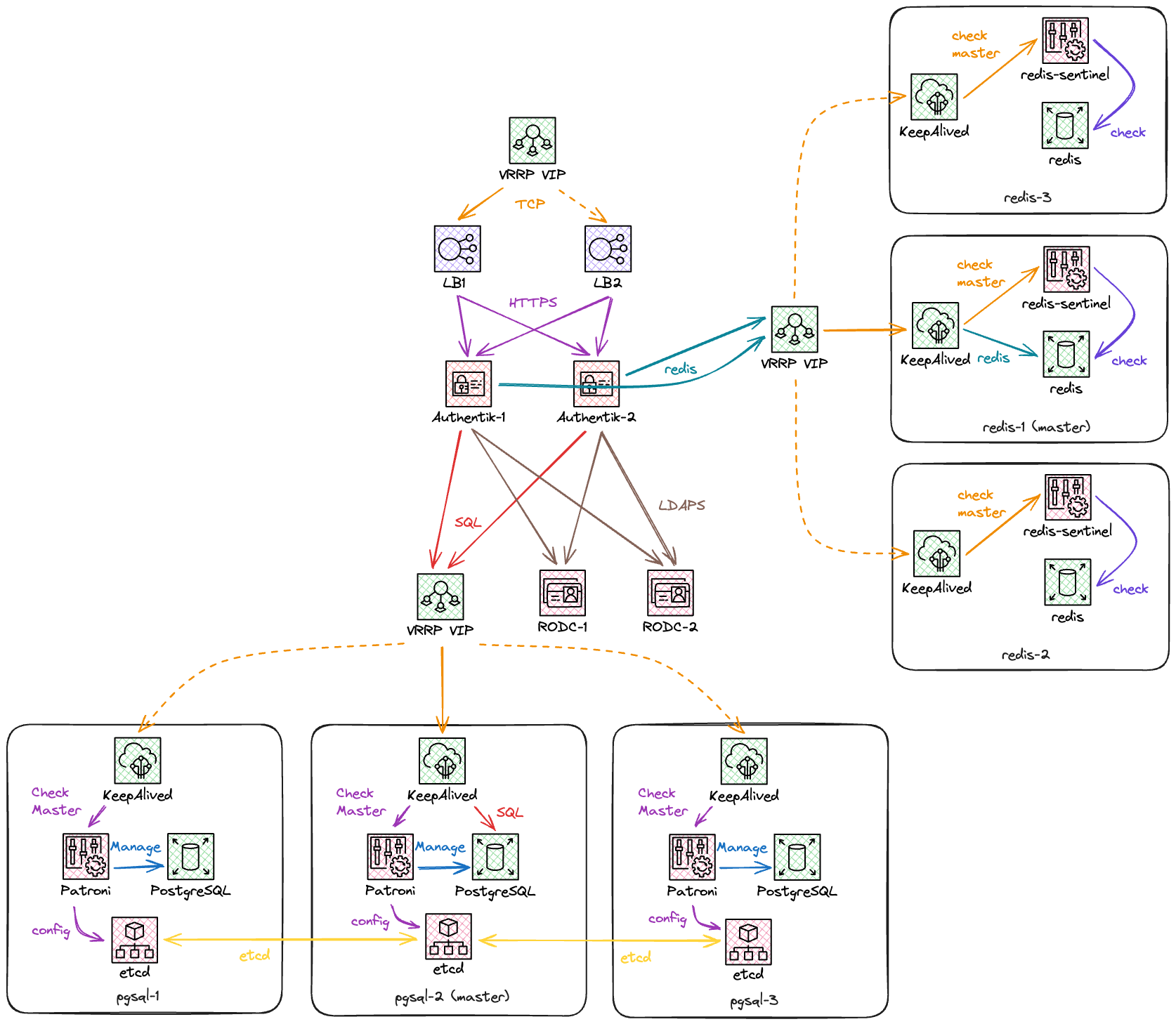
La seule partie que je n’ai pas abordée est celle des Load Balancers, que je juge assez peu intéressante car elle est assez générique. Elle comporte une paire de serveurs HAProxy, qui évaluent la santé des noeuds Authentik derrière eux et font proxy entre le client HTTPS et les serveurs Authentik.
On utilisera une nouvelle fois Keepalived sur ceux-ci, pour avoir une VIP qui répond en permanence, même si l’un des deux LB tombe.